高强钢氢含量预测及可解释性分析框架
冯少武1,崔梓煜,1,孙兴悦 2(1.天津大学化工学院;2.西北工业大学航空学院)
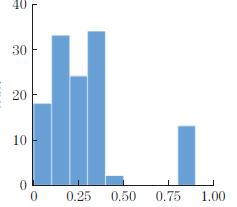
摘要: 构建了一个基于数据驱动方法的高强钢氢含量预测与可解释性分析框架,系统评估了人工神经网络(ANN)、支持向量机(SVM)、随机森林(RF)和极端梯度提升算法(XGBoost)4 种机器学习模型在多维特征空间下的预测性能,同时进一步利用SHAP(SHapley Additive exPlanations)方法开展可解释性分析,揭示12种元素(铁、碳、钼、锰、钛、钒、硅、铬、铜、镍、铝、铌)含量以及电流密度、温度、充氢时间、应变速率4 种试验条件对氢含量预测的贡献规律及其交互作用。结果表明:ANN、RF 和SVM 模型在训练集和测试集上预测氢含量的均方根误差和预测波动范围较大,部分预测结果在2 倍误差带外;XGBoost 模型在训练集和测试集上均具有较小的均方根误差和预测波动范围,预测结果均匀地分布在2 倍误差带内,该模型对高强钢氢含量的预测性能最佳。ANN 和SVM 模型的6 个特征(碳、锰、硅、铜含量,应变速率,充氢时间)对氢含量预测的贡献相对均衡,表明预测依赖多数特征的综合作用;RF 和XGBoost 模型的1~3 个特征(碳、锰或硅含量)的贡献显著更高,其余特征仅作为辅助信息,对预测结果的影响较小。高低特征值在正负贡献上混杂分布,说明氢含量与各特征存在显著非线性响应,并且预测结果受多特征间的复杂耦合效应影响。
关键词: 高强钢;机器学习;SHAP分析;氢含量预测
©软件著作权归作者所有。本站所有文件均来源于网络,仅供学习使用,请支持正版!
转载请注明出处!




发表评论 取消回复