本文回顾了过去十年中机器学习(ML)在材料科学研究中的发展,并探讨了未来的挑战和机遇。文章分析了在材料科学中应用机器学习时最常用的工具,包括软件、数据库、材料科学方法和机器学习方法,并指出尽管深度学习技术在增长,传统的机器学习技术仍然占据主导地位。本文还展示了在材料科学基准测试matbench上,形成焓预测的最佳分数随时间的进展,并特别强调了从使用传统机器学习的特征方法到使用图神经网络技术的转变,实现了7倍的错误降低。最后,文章提出了对未来挑战和机遇的看法,重点关注数据规模和复杂性、外推、解释性、获取和相关性等方面。
背景介绍
机器学习在材料科学领域的应用在过去十年中快速增长。这种增长表现为每年论文数量以大约1.67倍的速度增长,使得机器学习在材料研究中从一个小的细分领域发展成为材料科学与工程的一个重要子领域。到2023年,仅一年内就有超过2000篇关于材料机器学习的论文发表。此外,机器学习在材料科学中的应用已经扩展到模拟和建模、合成和表征、制造和文献挖掘等多个方面。研究背景还涉及到了机器学习技术的发展,如Transformer架构和晶体图神经网络,这些技术的发展推动了性能的重大进步,并避免了研究领域的停滞。文章的背景部分还强调了材料机器学习研究能够快速建立在以往工作的基础上,如数据库、软件、机器学习方法或特定领域的技术,这是该领域迅速发展的一个重要因素。
图解全文
图1 展示了机器学习在材料科学领域发表论文数量的年度增长情况。数据通过使用 pybliometrics Python 库从 Elsevier API 和 Scopus 数据库获取,时间截止到2024年1月23日。这张图直观地展示了从过去到现在,机器学习在材料科学研究中的兴趣和应用是如何快速增长的。通过这种趋势的可视化,可以清楚地看到这一领域研究活动的上升趋势,以及机器学习技术在材料科学中日益增长的重要性。
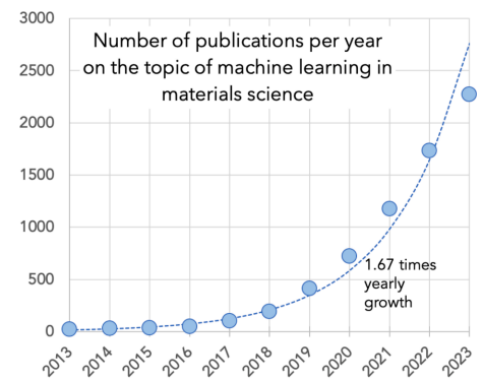
图1. 机器学习在材料科学领域发表论文数量的年度增长情况。
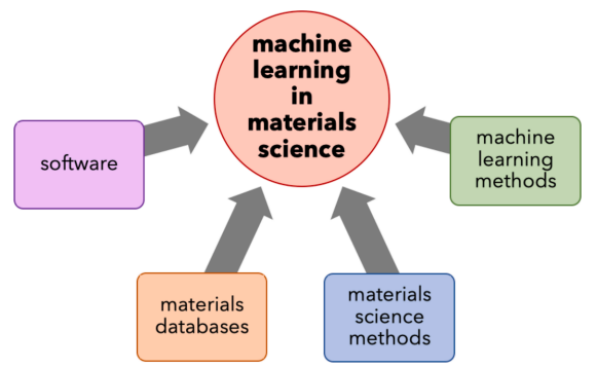
图2展示了机器学习在材料科学领域进步的推动因素。具体来说,它强调了软件、材料数据库、材料科学方法和机器学习方法的相互促进关系。这些因素共同作用,加速了机器学习在材料科学中的应用和发展。通过这种跨学科的合作和资源共享,研究者能够更快速地构建新的模型,提高预测材料性质的准确性,并开发出新的材料设计策略。
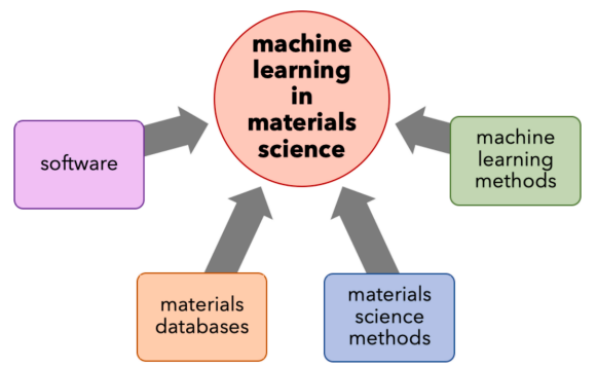 图2. 机器学习在材料科学领域进步的推动因素。
图2. 机器学习在材料科学领域进步的推动因素。
图3在文章中分析了在材料机器学习研究论文中引用次数超过100次的论文,以确定在此子领域内常用的工具和技巧。具体来说,图3关注了以下几个方面:(1)软件工具:分析了在材料机器学习领域中最常被使用的软件工具。其中,scikit-learn Python包是被引用次数最多的软件,这可能是因为它实现了多种对材料机器学习有用的技术,并且适用于各种材料问题。VASP软件是下一个被高度引用的工具,它与其它几个软件库(如pymatgen、Phonopy、matminer和AFLOW)通常用于通过密度泛函理论(DFT)计算或分析材料属性。(2)数据库:分析了在材料科学机器学习(MSE-ML)论文中被引用次数最多的数据库,这些数据库(如Materials Project、OQMD和AFLOWLib.org)主要关注基于密度泛函理论生成的数据集。(3)机器学习方法:分析了在材料领域应用的、不依赖特定领域的机器学习方法。发现传统的基于树的机器学习技术(如随机森林、XGBoost和梯度提升)是最占主导地位的。尽管深度学习的使用正在变得日益流行,但训练这些算法所需的更大数据集可能限制了它们的更广泛使用。(4)材料科学方法:检查了为材料科学领域开发的常用方法,包括模拟方法(如DFT-GGA、分子动力学、DFT-Monkhorst Pack和从头算分子动力学-AIMD)、材料描述符(如Magpie描述符、SOAP描述符、Coloumb矩阵等),以及用于ML力场的方法(如Behler-Parrinello势、GAP势、SNAP势和深度势)。图3的分析结果表明,尽管深度学习技术在某些任务(如语言建模或图像生成)中表现出色,但在材料领域,传统的机器学习技术仍然比深度学习技术更受欢迎。此外,常见的数据库、软件库和技术现在已可供基于模拟的机器学习使用,但在材料科学的其他领域(如合成、表征和材料加工数据)仍然需要类似的大型和协调的研究社区努力。
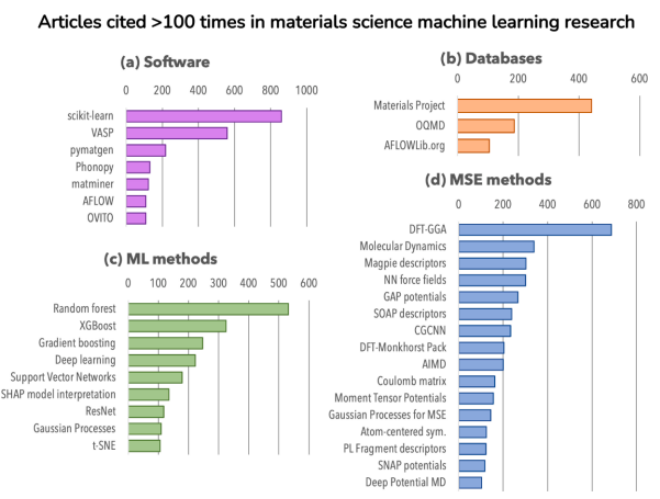
图3. 对材料机器学习领域内引用次数超过100次的论文的分析。
表1 提供了 matbench 基准测试的当前快照,显示了不同材料属性预测任务的当前最佳算法及其验证后的平均绝对误差(MAE)或接收者操作特征曲线下面积(ROC-AUC)。这些任务根据样本数量(即数据点)进行排序,涵盖了从312个样本到132,752个样本的不同规模数据集。表中列出了以下任务及其对应的最佳算法和性能指标:
表1. 2024年1月23日matbench排行榜的当前快照。
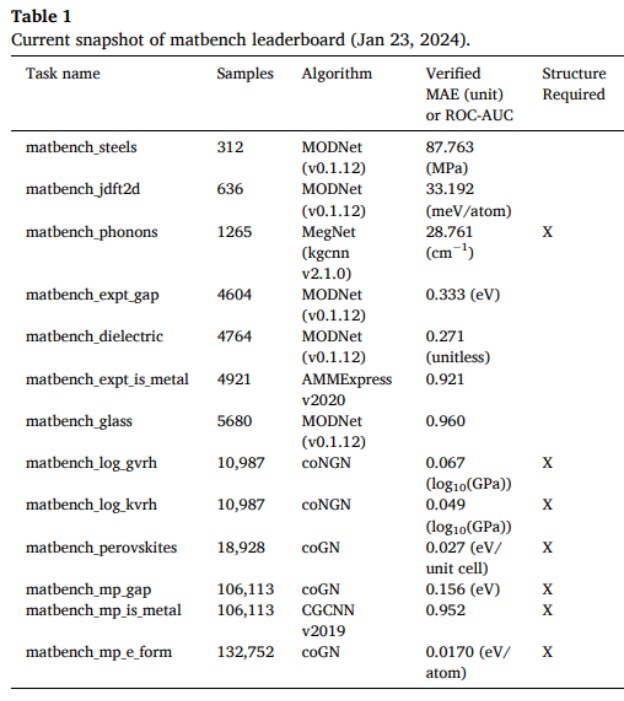
图4 在文章中展示了在预测材料的形成焓(formation enthalpies)方面,不同机器学习模型随时间推移所取得的进展。这些形成焓是通过密度泛函理论(density functional theory, DFT)模拟计算并由Materials Project数据库整理的。图中特别强调了从使用传统机器学习的特征方法(例如,基于Magpie描述符的随机森林模型)到采用图神经网络技术(如CGCNN,Crystal Graph Convolutional Neural Network)的转变,这一转变带来了显著的性能提升,即均方绝对误差(mean absolute error, MAE)的大幅下降。 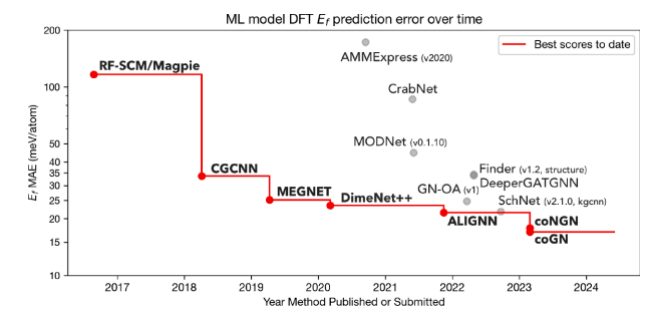
图4. 各种机器学习模型在较小数据任务(弹性常数)和较大数据任务(形成焓)上取得的进展。
图5 在文章中提供了对材料机器学习领域当前面临的主要挑战和未来机遇的概览。这张图概述了五个关键领域,并讨论了每个领域当前的进展和未来的需求。以下是这五个领域的总结:第一,数据规模和复杂性:材料数据可能数量有限且复杂度高。自然语言处理技术的进步有助于从科学文献中提取结构化数据集。需要新的方法来处理小数据集,例如多保真度建模、混合特征化和神经网络,以及迁移学习。第二,外推能力:目前缺乏量化机器学习模型外推限制的明确标准。需要新的方法,如LOCO-CV,来评估模型在训练集之外的泛化能力。对于开放性探索(如迭代机器学习或生成模型)的评估,需要进一步的研究。第三,解释性:可解释模型有助于揭示物理洞见和关系,而不仅仅是做出预测。存在多种模型无关的解释方法,但这些方法并不能完全捕捉或解释底层模型的决策过程。需要在模型内部构建解释性或限制模型使用符号回归。第四,获取和访问:访问问题日益成为一个挑战,尤其是对于基于专有数据集训练的专有模型。模型和数据集的获取问题对于开放科学和研究的可重复性至关重要。需要考虑如何使研究成果能够独立于特定模型或数据集进行验证。第五,相关性:机器学习模型的最终目标是服务于实际的材料发现和设计。需要更多关注如何将计算预测与自动化实验室紧密结合,并验证计算建议。机器学习在材料科学中的应用需要与实验验证和实际应用更紧密地整合。

图5. 材料机器学习中的主要挑战和机遇概览。
总结展望
过去十年中,机器学习在材料科学领域取得了显著进展,研究论文数量呈指数级增长,传统机器学习技术尽管在某些领域受到深度学习技术的挑战,但仍占主导地位;未来,该领域面临的挑战包括扩大数据规模和复杂性、提高模型的外推能力、增强模型的解释性、确保模型和数据的可访问性以及加强机器学习预测与实验验证的整合,这些挑战的克服将推动材料科学向更精准、高效的方向发展。
DOI: 10.1016/j.cossms.2024.101189
(来源:材料与人工智能)


发表评论 取消回复