据英国主导的OpenBind项目官网消息,当地时间5日,OpenBind发布首个公开可用的数据集和预测型人工智能(AI)模型“OpenBind v1”,旨在利用高质量实验数据推动AI辅助药物研发。这是利用AI加速发现新药的突破性一步,标志着该项目已具备持续、大规模生成“AI就绪”药物研发数据的能力,为开发新一代药物发现AI工具奠定了基础。
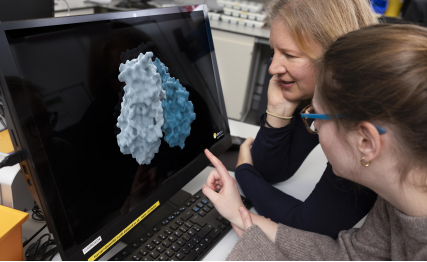 牛津大学“药物发现中心”团队负责人莉兹贝·库克莫尔与英国钻石光源同步辐射设施研究人员雅丝敏·阿申布伦纳在钻石实验室查看分子结构。
牛津大学“药物发现中心”团队负责人莉兹贝·库克莫尔与英国钻石光源同步辐射设施研究人员雅丝敏·阿申布伦纳在钻石实验室查看分子结构。
图片来源:OpenBind官网
近年来,AI已显著提升了蛋白质结构预测的准确性,但其在药物研发领域的应用进展相对有限。研究人员认为,关键原因在于全球范围内缺乏高质量实验数据,难以精确描述药物分子与疾病相关蛋白之间的结合方式。OpenBind项目正是为填补这一空白而建立的。
据介绍,此次发布的数据集包含约800项实验测量结果,涉及药物分子与相关蛋白的结合信息。项目团队称,这批数据在7个月内完成采集,而类似规模的数据集过去通常需要更长时间才能公开。
研究过程中,团队结合了自动化化学实验、结构测量、高通量晶体学分析以及AI模型训练等方法,并利用英国Isambard-AI超级计算设施开展计算工作。
美国哥伦比亚大学教授穆罕默德·阿尔库莱希表示,蛋白质结构预测模型“阿尔法折叠2”之所以能够推动蛋白质结构预测取得突破,很大程度上依赖于蛋白质数据库中长期积累的大量实验数据。而针对“蛋白质—药物复合物”的同类开放数据资源目前仍十分缺乏,OpenBind希望建立这一关键基础设施,并据此开发下一代药物—蛋白相互作用预测工具。
研究人员表示,项目运行过程中发现,实验流程的标准化、元数据管理以及自动化程度,会直接影响数据的一致性和可重复性,而这些因素又与AI模型的训练效果密切相关。
按照计划,OpenBind后续将扩大数据规模,并增加更多疾病相关研究目标,包括COVID-19、疟疾、登革热、寨卡病毒和癌症等方向。
(来源:科技日报 记者:张佳欣)


发表评论 取消回复